
오늘은 데이터 분석 종합반 4주차 강의를 수강 및 학습했다. 지금까지는 주어진 데이터를 상황에 맞게 검증했지만, 이번에는 직접 가설을 세워보고 검증하는 연습을 했다.

미션의 목표는 게임종합반 구매전환률을 높여라다.
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic') # 라이브러리 불러오고 폰트 세팅
sparta_data = pd.read_csv('/content/user_db1.csv')
sparta_data = sparta_data.dropna()
sparta_data
우리가 받은 데이터에는 user_id, 성별, 지역, 나이, 유입 경로, group(할인 쿠폰 사용 여부)가 담겨있다.
(1) 우선적으로 광고 효율을 살펴보자. 효율이 나지 않는 광고 매체를 찾아서 예산을 줄이고 다른 매체에 예산을 늘리는 것이 좋아보인다.
access_media = sparta_data.groupby('access_media')['user_id'].count()
import matplotlib.pyplot as plt
import numpy as np
plt.rc('font', family='NanumBarunGothic')
access_media이제는 익숙한 groupby를 통해 유입 경로 기준으로 user_id수를 카운팅해준다.
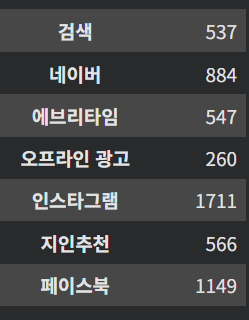
데이터 확인 결과, 인스타그램으로 유입된 수강생의 수가 가장 많았고 오프라인 광고로 유입된 수강생의 수가 가장 적었다.
#plt.figure(width, height) : 넓이와 높이 만큼 이미지를 생성한다는 것을 말해줍니다!
plt.figure(figsize=(6,6))
#width=원하는 두께로 그래프의 바 너비를 변경 할 수 있어요! 기본 값은 0.8입니다!
plt.barh(access_media.index,access_media.values)
#그래프의 제목
plt.title('수강생 별 수강 신청 경로',fontsize=10)
#그래프의 x축 라벨 이름
plt.xlabel('수강 신청 경로')
#그래프의 y축 라벨 이름
plt.ylabel('수강생 수')
#x축 눈금의 글씨의 각도 변경을 위해 plt.xticks(rotation="원하는 각도")를 이용해요!
#x축 눈금의 글씨를 45도 회전
plt.xticks(rotation=45)
#그래프를 화면에 나타나도록 합니다.
plt.show()이후 데이터를 라이브러를 이용하여 시각화해주었다.

plt.barh(access_media.index,access_media.values)이때 평소에 사용하면 bar대신 barh를 이용하여 그래프를 옆으로 뒤집어줘서 가시성을 높여보았다.
따라서, 옥외광고 비율을 줄이고, 광고 효율이 좋은 인스타 그램, 페이스북 그리고 네이버 블로그 관련 홍보에
예산을 집중하는 것이 좋다는 결론을 내릴 수 있었다.
(2) 게임개발 종합반이 다른 패키지에 포함되어 있는 강의들 보다 구매 전환율이 저조한 상황이라 매력적인
패키지 상품을 기획하여 게임개발 종합반의 구매 전환율을 더욱 높이는 것이 좋아보인다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic') #한글 깨짐 방지 글꼴 설정
sparta_data = pd.read_table('/content/user_registered_class.csv',sep=',')
sparta_data
이번 데이터는 게임개발 종합반 과목을 산 인원이 동시에 구입한 과목들을 나타내는 데이터이다. 게임개발 종합반 과목을 산 인원 중 가장 많은 인원이 동시에 구입한 과목과 패키지를 기획해 판매한다면 구매 전환율을 높일 수 있을 것이다.
sum_of_students_by_class = sparta_data[sparta_data==1].count()
sum_of_students_by_class = sum_of_students_by_class.drop('user_id')
sum_of_students_by_class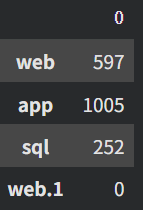
이번에는 groupby대신 패키지를 구매한 수강생의 수만 세기 위하여 조건문을 사용하였다.
#그래프 사이즈 설정
plt.figure(figsize=(10,5))
#각각 어떤 값이 들어가야 하는지 입력해 볼까요?
#plt.bar(X축값, Y축값)
plt.bar(sum_of_students_by_class.index ,sum_of_students_by_class)
#그래프 타이틀
plt.title('게임개발 종합반 신청한 학생 수강이력')
#x축 레이블
plt.xlabel('강의')
#y축 레이블
plt.ylabel('수강생(명)')
#그래프 보여주기
plt.show()이후 시각화를 통해 확인한 결과
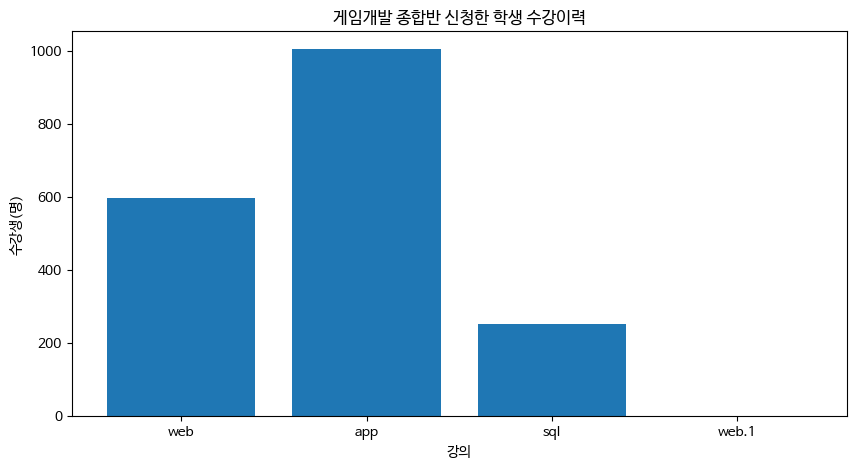
게임개발 종합반 과목을 수강한 학생들이 가장 많이 추가적으로 신청한 과목은 앱개발 종합반 과목이었다.
그런데 여기서 왜 게임개발 종합반 과목을 수강한 학생들이 앱개발 종합반 과목을 가장많이 들었을까?라는 의문점이 생겼다
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic') #한글 깨짐 방지 글꼴 설정
sparta_data_app = pd.read_table('/content/user_db_app.csv',sep=',')
sparta_data_game = pd.read_table('/content/user_db_game.csv',sep=',')
sparta_data_app
sparta_data_game
이번에는 그 의문점을 해결하기위해 앱개발 종합반 강의 수강생과 게임개발 종합반 강의 수강생의 관심사를 확인해보기로 했다.
app_users_goal = sparta_data_app.groupby('goal')['user_id'].count()
game_users_goal = sparta_data_game.groupby('goal')['user_id'].count()
#그래프 크기 설정 (인치)
plt.figure(figsize=(8,6))
#x축 y축 설정을 동일하게 해주고, color와, label을 추가 해주시면 됩니다. 참 쉽죠?
#app 종합반 수강생 관심 분야
plt.plot(app_users_goal.index ,app_users_goal,color="red", label="app")
#game 종합반 수강생 관심 분야
plt.plot(game_users_goal.index ,game_users_goal,color="blue", label="game")
#각 그래프의 범례는 .legend()을 이용하여 만들어 줍니다!
plt.legend()
#그래프 타이틀
plt.title("앱 종합반, 게임 종합반 수강생의 관심사")
#x축 레이블
plt.xlabel('수강 목적')
#y축 레이블
plt.ylabel('수강생 수')
#그래프 보여주기
plt.show()groupby를 통해 관심사를 기준으로 user_id 수를 세어 앱과 게임개발 종합반 수강생들의 관심사를 plot으로 시각화 하였다.
이때 두개이상의 그래프를 동시에 나타내기 때문에 plt.legend()를 넣어 범례를 만들어줬다.
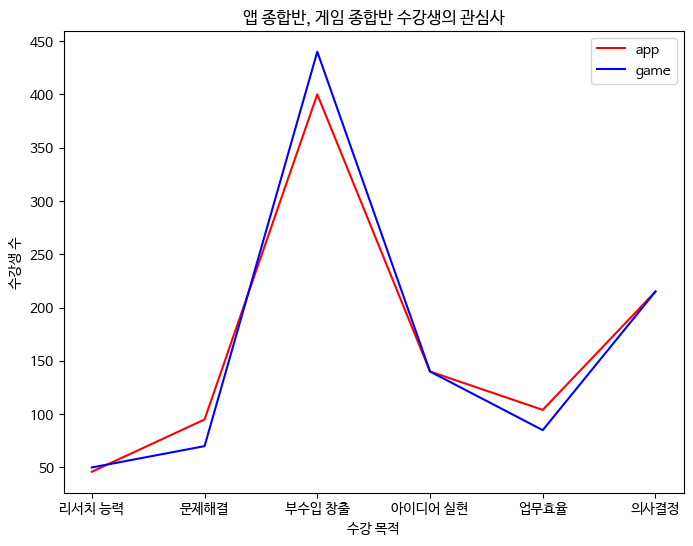
그래프를 통해 게임개발 종합반 강의 수강생들이 앱개발 종합반 강의도 수강한 이유는 부수입 창출이라는 수강 목적 때문이었음을 확인할 수 있었다. 따라서, 게임종합반 구매전환률을 높이기 위해서 부수입 창출 키워드로 패키지 상품을 만들어 파는것이 좋을 것이다.
(3) 할인쿠폰이 구매전환율에 긍정적인 영향을 준다면 할인쿠폰을 더 자주 배포하는 것이 좋을것이다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic') #한글 깨짐 방지 글꼴 설정
sparta_data = pd.read_table('/content/user_db1.csv',sep=',')
users_discount = sparta_data[sparta_data['group']==1]['user_id'].count()
users_not_discount = sparta_data[sparta_data['group']==0]['user_id'].count()
#그래프 사이즈
plt.figure(figsize=(10,5))
#x 그룹 지정하기
x_list =["정가 구입 그룹", "할인 적용 그룹"]
#y 값
#각각 어떤 값이 들어가야 하는지 입력해 볼까요?
y_list = [users_not_discount ,users_discount]
#x,y값 설정
plt.bar(x_list, y_list)
#그래프 타이틀
plt.title('할인 여부 결제 전환율 비교 분석')
#x축 레이블
plt.xlabel('할인 적용 여부')
#y축 레이블
plt.ylabel('결제 전환율')
#그래프 보여주기
plt.show()(1)에서 사용했던 할인쿠폰 사용 여부가 담겨있는 데이터를 가져와 할인쿠폰을 사용한 그룹과 사용하지 않은 그룹으로 나누었고 각각의 경우에 대한 수강생의 수를 계산하여 시각화했다.
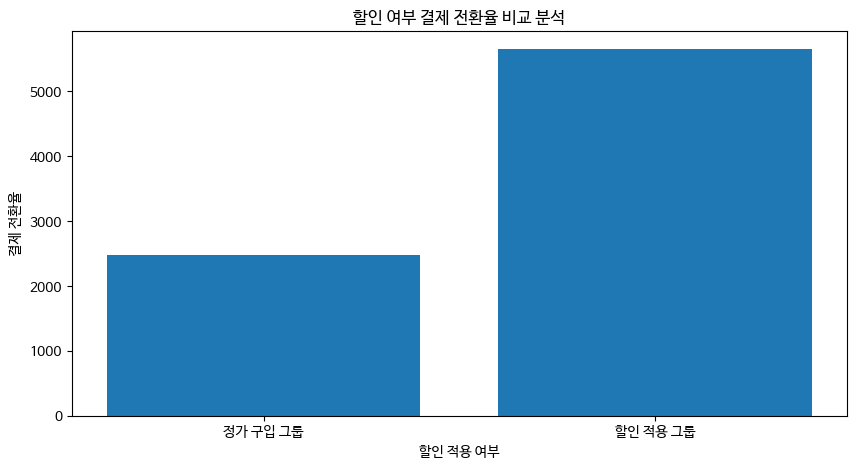
그레프를 통해, 할인 쿠폰을 사용한 그룹의 수강전환 비율이 더욱 높았다. 즉, 가설이 맞았고 추가적인 할인 쿠폰 배포를 통해 수강전환율을 늘릴 수 있을 것이다.
오늘은 어제 공부했던 내용과 코드 측면에서는 크게 다르지 않았지만, 여러 가설을 세우고 검증하는 것만으로도 같은 데이터를 더 유용하게 분석할 수 있다는 것을 알게되었다. 점점 데이터분석에 익숙해지고 있는 느낌인데, 이 페이스를 유지하며 꾸준히 달려가야겠다.
'내일배움캠프 > TIL(Today I Learned)' 카테고리의 다른 글
| [2026/03/16] 내일배움캠프 6일차 TIL & KPT 회고 (0) | 2026.03.16 |
|---|---|
| [2026/03/13] 내일배움캠프 5일차 TIL (0) | 2026.03.13 |
| [2026/03/11] 내일배움캠프 3일차 TIL (0) | 2026.03.11 |
| [2026/03/10] 내일배움캠프 2일차 TIL (0) | 2026.03.10 |
| [2026/03/09] 내일배움캠프 1일차 TIL&커리어스터디 (0) | 2026.03.09 |