
오늘은 데이터 분석 종합반 3주차 강의를 수강 및 학습했다. 본격적으로 colab을 사용하기 시작했고, 데이터를 내가 필요한대로 가공하는 방법과 히트맵으로 나타내는 방법을 배웠다.

오늘의 미션은 무슨 요일, 몇시에 수강생들이 강의를 듣는지 알아보고 가장 적절한 고객 관리 타이밍을 분석하는 것이다.

csv 파일의 데이터는 lecture_id, access_date, user_id로 구성되어있고 우리는 access_date의 정보를 활용하여 수강생들이 강의를 듣는 요일과 시간을 파악하려고 한다.
import pandas as pd
sparta_data = pd.read_table('/content/access_detail.csv', sep=',')
sparta_data.head()
# print(type(1))
# print(type("hello"))
print(type(sparta_data["access_date"][0])) # 컴퓨터가 날짜정보를 문자정보로 인식하고 있음하지만, access_date의 자료형을 확인해 본 결과 컴퓨터가 날짜정보를 문자정보로 인식하고 있어서 요일과 시간 정보로 나타내기가 어려웠다.
format='%Y-%m-%d %H:%M:%S'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format, errors='coerce')
sparta_data.tail(5)
print(type(sparta_data["access_date_time"][0]))따라서 pandas 라이브러리를 이용하여 access_date_time의 정보를 날짜 정보로 변환시켜주기 위해 format을 지정해주었다.
<class 'str'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
결과적으로 access_date_time의 class가 'str'에서 'Timestamp'로 변환되어 우리가 원하는 정보를 추출할 수 있게 되었다.
sparta_data['access_date_time_weekday'] = sparta_data['access_date_time'].dt.day_name()
sparta_data['access_date_time_hour'] = sparta_data['access_date_time'].dt.hour
sparta_data.tail(5) # 요일 및 시간 정보만 따로 확인 가능
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata이후 access_date_time_weekday와 access_date_time_hour 항목을 만들어 요일 및 시간 정보만 따로 추출했다.
그리고 요일마다의 수강생 수를 확인하기 위해 weeks 리스트를 정의했다.

결과적으로 요일별 수강생의 수를 확인할 수 있게 되었다.
hourdata = sparta_data.groupby('access_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index(ascending=False) # 내림차순 정렬
hourdata이후 시간에 대해서도 동일한 코드를 작성하여 시간데이터를 추출해냈다.
import matplotlib.pyplot as plt
import numpy as np # 연산을 용이하게 해주는 라이브러리
#그래프 사이즈
plt.figure(figsize=(10,5)) # 가로 세로 비율
plt.rc('font', family='NanumBarunGothic')
#그래프 x축 y축 (제일 중요한 요소)
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()이제 추출한 데이터를 바탕으로 matplotlib 라이브러리를 이용하여 bar 형태의 그래프로 나타냈다.

데이터를 시각화하니, 화요일에 가장 많은 수강 완료 수강생이 있음을 확인할 수 있었다.
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(hourdata.index, hourdata) # bar 대신 plot 사용함
#그래프 명
plt.title('시간별 수강 완료 사용자 수')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 표시 하기
plt.xticks(np.arange(24)) # 안넣을 경우 0 5 15 20 이렇게 가로 눈금이 표시됨
#그래프 출력
plt.show()시간에 대해서도 동일하게 코드를 작성하여 plot 형태의 그래프로 나타냈다.
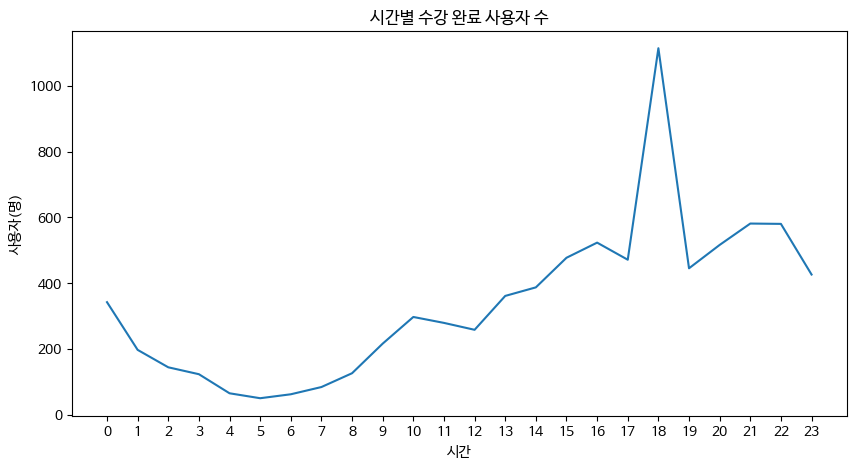
오후 6시에 가장 많은 수강 완료 사용자가 있음을 확인할 수 있었다.
하지만, 우리가 이렇게 두개로 그래프를 나누면 그래프 두개를 번갈아 봐야 데이터를 파악할 수 있어서 불편함이 존재했다.
따라서, 한눈에 파악을 할 수 있는 히트맵 그래프로 나타내보기로 했다.
#피벗테이블 만들기
sparta_data_pivot_table = pd.pivot_table(sparta_data, values='user_id',
index=['access_date_time_weekday'],
columns=['access_date_time_hour'],
aggfunc="count").agg(weeks)
sparta_data_pivot_table히트맵 출력을 위해 피벗 테이블을 만들어서 행/열을 지정해주고
#그래프 사이즈 변경
plt.figure(figsize=(14,5))
#pcolor를 이용하여 heatmap 그리기
plt.pcolor(sparta_data_pivot_table)
#히트맵에서의 x축
plt.xticks(np.arange(0.5, len(sparta_data_pivot_table.columns), 1), sparta_data_pivot_table.columns)
#히트맵에서의 y축
plt.yticks(np.arange(0.5, len(sparta_data_pivot_table.index), 1), sparta_data_pivot_table.index)
#그래프 명
plt.title('요일별 종료 시간 히트맵')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('요일')
#plt.colorbar() 명령어를 추가하면 그래프 옆에 숫자별 색상값을 나타내는 컬러바를 보여 줍니다
plt.colorbar()
plt.show()히트맵 형태의 그래프로 나타내기위한 코드를 작성했다.

이때, 숫자 눈금이 각 단위 사각형의 중간부분에 오도록 가로축을 0.5만큼 오른쪽으로 옮겨 주었다.
이렇게 히트맵으로 나타내자, 화요일 오후 6시에 수강을 완료한 수강생이 가장 많음을 한눈에 확인 할 수 있었다.

이번에는 지역에 관한 데이터를 분석해보는 미션을 받았다.

csv 파일의 데이터는 lecture_id, area, latitude, longitude, user_id로 구성되어있고 우리는 area의 정보를 활용하여 수강생들이 강의를 듣는 지역을 파악하려고 한다.
import pandas as pd
sparta_data = pd.read_table('/content/students_area_detail.csv',sep=',')
category_range = set(sparta_data['area']) # 중복된 값을 없애줌
print(category_range, len(category_range))
#새로운 테이블을 만들고자 할 땐 기존의 테이블에서 필요한 "열의 이름"을 대괄호에 넣어 변수에 지정해 주면 됩니다
area_info=sparta_data[['area','latitude','longitude']]
#drop_duplicates()을 이용하면, area(지역) 컬럼의 중복 데이터를 처리 할 수 있습니다. :)
area_info=area_info.drop_duplicates(['area']) # area값이 duplicate되면 날려라
area_info = area_info.sort_values(by=["area"], ascending=[True]) # ㄱ,ㄴ,ㄷ 순 정렬
area_info= area_info.reset_index() # 인덱스 다시 0부터 달아줌
number_of_students = pd.DataFrame(sparta_data.groupby('area')['user_id'].count())
#merge()를 이용하여, 두 테이블을 병합 할수 있어요 :)!
result = pd.merge(area_info, number_of_students, on="area")
result이전 미션의 경우 weeks를 우리가 Monday~Friday라는것이 고정되어 있었지만, 이번에는 지역의 종류를 데이터로부터 추출하여 리스트화 할 필요성이 있었다. 따라서 category_range에 set 함수를 이용하여 지역 리스트를 만들어 줬다.
{'경기', '광주', '강원', '전북', '경북', '제주', '경남', '서울', '부산', '충북', '세종', '대전'} 12
총 12개의 지역에 해당하는 수강생들이 존재함을 알 수 있었다.
이후 중복 데이터를 처리하고, merge를 이용하여 테이블을 병합하여 보기 데이터를 가공했다.
import matplotlib.pyplot as plt
import numpy as np
plt.rc('font', family='NanumBarunGothic') #한글 깨짐을 방지시켜줘요!
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(result['area'], result['user_id'])
#그래프 명
plt.title('지역별 사용자 수')
#그래프 x축 레이블
plt.xlabel('지역')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 수
plt.xticks(np.arange(13))
#그래프 출력
plt.show()이제 가공한 데이터를 시각적으로 나타내기위해 matplotlib 라이브러리를 이용하여 plot 형태의 그래프로 나타냈다.
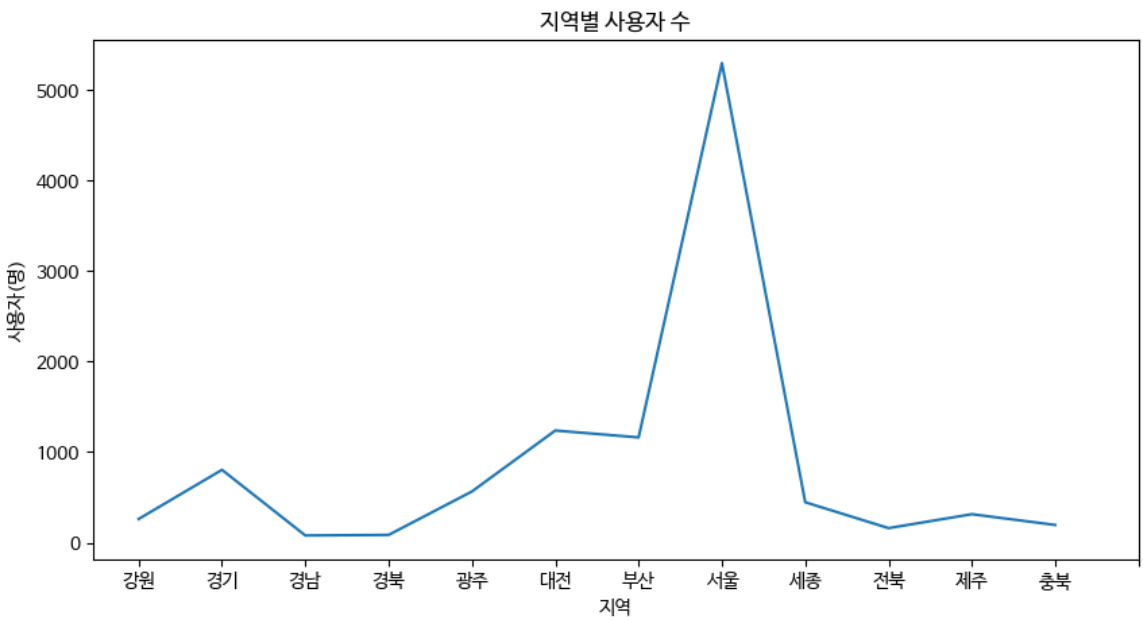
대한민국의 수도답게 서울의 사용자 수가 가장 많음을 한눈에 확인할 수 있었다. 하지만, 지역을 나타내는데 있어서 plot 그래프는 뭔가 아쉬움이 있었다.
지역별 사용자 수의 분포를 보고자 할 때 가장 좋은 것은 무엇이 있을까?
정답은 지도이다.
# 필요한 라이브러리 사용 선언하기
import folium
from folium.plugins import MarkerCluster
m = folium.Map(location=[37.5536067,126.9674308],
zoom_start=11)
for n in result.index:
radius = result.loc[n,'user_id']
#loc[n,"열 이름"] => loc[]를 활용하여 n번째의 열을 조회 할수 있습니다!
#즉, n번째의 user의 수를 가져 올수 있는 것이죠!
folium.CircleMarker([result['latitude'][n],result['longitude'][n]],
radius = radius/50, fill=True).add_to(m)
#.add_to(m)를 활용하여, 지정해 두었던 우리나라의 지도를 가져올 수 있습니다!
m지도에 분포를 나타낼 수 있는 시각적 데이터를 만들어내기위해 folium 라이브러를 가져왔다.
이후 for문을 이용하여 'user_id'수 만큼 원의 지름이 늘어나도록 설정하여 지도에 나타냈다.
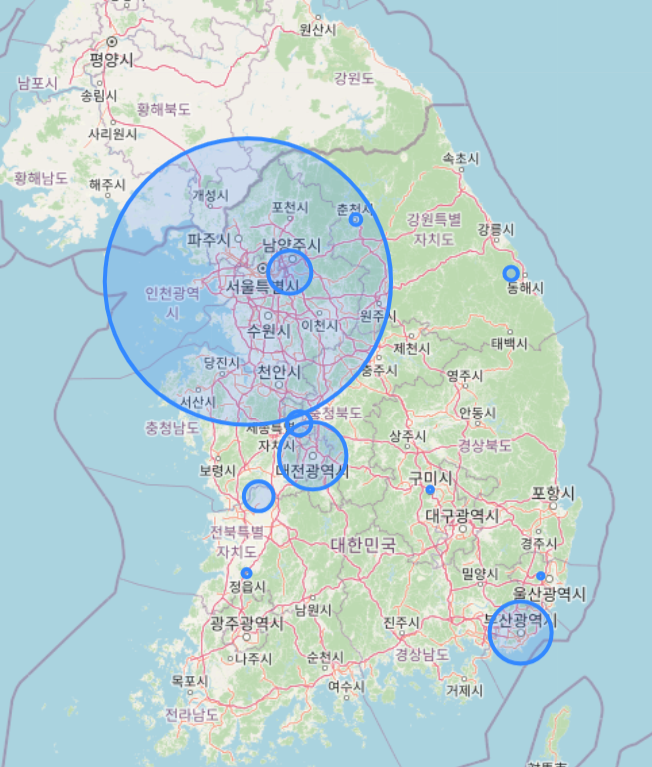
결과적으로 이렇게 지도에서 시각적으로 분포를 확인할 수 있게 되었고 plot 형태보다 직관적으로 데이터를 이해할 수 있었다.
오늘은 데이터를 가공하고 다양한 시각적 자료로 변환하는 방법을 익혔다. 여러가지 라이브러리가 가져다주는 기능들을 활용하다보니 파이썬의 활용도가 무궁무진하다고 느껴졌고 하나씩 확실하게 배워가기로 다시 한번 다짐했다.
'내일배움캠프 > TIL(Today I Learned)' 카테고리의 다른 글
| [2026/03/16] 내일배움캠프 6일차 TIL & KPT 회고 (0) | 2026.03.16 |
|---|---|
| [2026/03/13] 내일배움캠프 5일차 TIL (0) | 2026.03.13 |
| [2026/03/12] 내일배움캠프 4일차 TIL (0) | 2026.03.12 |
| [2026/03/10] 내일배움캠프 2일차 TIL (0) | 2026.03.10 |
| [2026/03/09] 내일배움캠프 1일차 TIL&커리어스터디 (0) | 2026.03.09 |