
오늘은 데이터 분석 종합반 5주차 강의를 수강 및 학습했다. 오늘은 지금까지 배웠던 데이터 분석 종합반 내용들을 모두 종합하여 활용하고 추가적으로 데이터 가공 방법에 대해서 자세하게 배웠다.

오늘 주어진 과제는 완주율이 떨어진 이유 찾기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rc('font', family='NanumBarunGothic') #한글 깨짐 방지 설정
sparta_data = pd.read_csv('/content/sparta_data.csv')
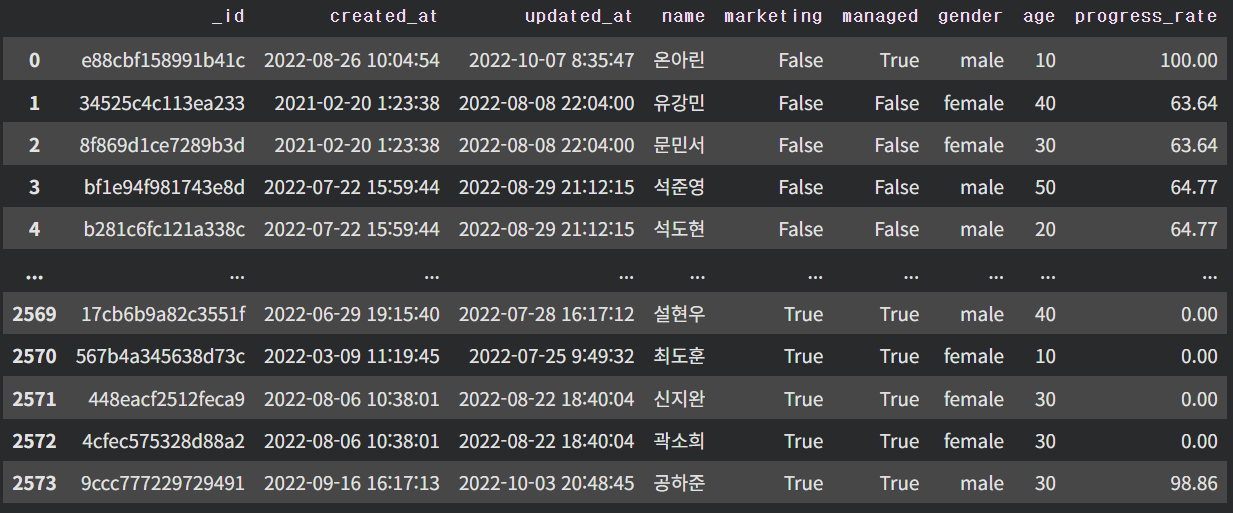
#_id, created_at, updated_at, name, marketing, managed, gender, age, progress_rate
cohort_data = pd.read_csv('/content/cohort_data.csv')
#created_at, usder_id, name, progress_rate
sparta_data = sparta_data.dropna()
cohort_data = cohort_data.dropna()(1) 나이대별 완주율을 비교
우선 sparta_data의 항목은 아래와 같다
# PART1 가설 1
student_age_sum = sparta_data.groupby('age')['progress_rate'].sum()
student_age_num = sparta_data.groupby('age')['_id'].count()
student_age_num #20s 1043
average = student_age_sum / student_age_num
plt.figure(figsize=(6,6))
plt.xticks([10,20,30,40,50])
plt.bar(average.index, average, width=8)
bar = plt.bar(average.index, average,width=8)
for rect in bar:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2.0, height, '%.1f' % height, ha='center', va='bottom', size = 12)
plt.title('[나이대 별 평균 수강율]',fontsize=15,pad=20)
plt.xlabel('나이',fontsize=12,labelpad=20)
plt.ylabel('수강생(명)',fontsize=14,rotation=360,labelpad=35)
plt.show()
groupby를 이용해 나이 기준으로 진도율와 나이별 수강생 수에 대한 데이터를 뽑아냈다.
이후, 진도율의 합을 수강생의 수로 나누어 나이대별 수강율의 평균을 계산한 뒤 bar 형태로 나타냈다.
이때 for문을 통해 %값을 그래프위 bar 위에 표시해주었는데. x좌표값에 bar 뚜게의 절반을 더해주어 숫자의 위치가 중간에 올 수 있도록 조절해줬다.

결과적으로, 나이대에 따른 수강율의 차이가 크지 않았다.
(2) 관리여부 별 완주율
# PART2 가설
managed = ['TRUE','False']
student_manage_sum = sparta_data.groupby('managed')['progress_rate'].sum()
student_manage_num = sparta_data.groupby('managed')['_id'].count()
average = student_manage_sum/student_manage_num
plt.figure(figsize=(6,6))
plt.xticks([0,1], labels = ["비 신청자",'신청자'])
plt.bar(average.index, average, width=0.5)
bar = plt.bar(average.index, average,width=0.5)
for rect in bar:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2.0, height, '%.1f' % height, ha='center', va='bottom', size = 12)
plt.title('[관려 여부 별 평균 수강율]',fontsize=15,pad=20)
plt.xlabel('관리 여부',fontsize=12,labelpad=20)
plt.ylabel('수강율',fontsize=14,rotation=360,labelpad=35)
plt.show()이번에는 managed를 정의하여 관리여부를 TRUE, FALSE로 지정하고 groupby를 통해 관리여부에 따라 진도율과 수강생의 수를 뽑아내서 (1)에서와 동일한 작업을 해주었다.
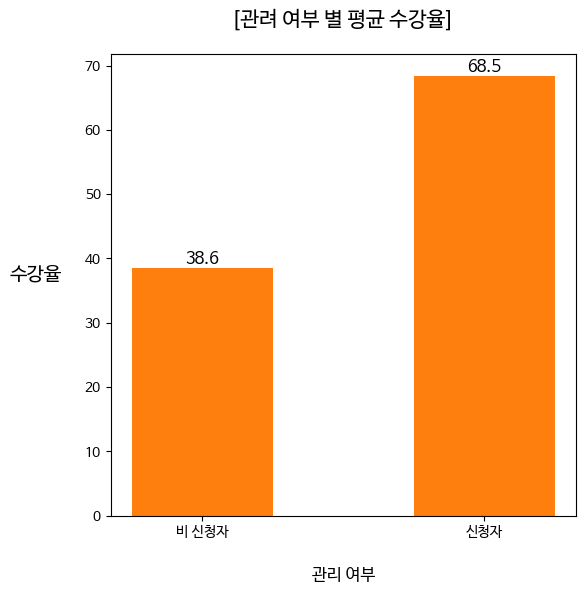
결과적으로 관리 여부가 수강율에 긍정적인 영향을 주었다고 볼 수 있었다.

(3) 마지막 목표는 3주차 컨텐츠에 변동사항이 있었고, 이후 완주율이 꺾인 상황에서 컨텐츠 변동사항이 완주율에 준 영향을 확인하는 것이었다. 이번 목표 해결 과정은 정말 어려웠다. 아래는 cohort_data의 내용이다.

format = "%Y. %m. %d"
cohort_data['start_time'] = pd.to_datetime(cohort_data['created_at'], format='mixed')
#수강 시작 주 구하고, 테이블의 열로 추가 하기
cohort_data['start_week']= cohort_data['start_time'].dt.isocalendar().week
# dt.isocalendar().week는 ISO 8601 달력 시스템에 따라 주 번호 정보를 추출한다
#이전에 배웠듯이 set()은 set안의 데이터는 순서가 정해져있지 않고, 중복되지 않는 고유한 요소를 가져옵니다!
category_range = set(cohort_data['start_week'])
progress_rate = list(cohort_data['progress_rate'])우선 created_at 항목이 str로 인식되기 때문에 이전에 배웠듯이 format을 지정하여 날짜 정보로 바꾸어주었다.
그리고 isocalender().week를 이용하여 해당 날짜가 몇번 째 주인지에 대한 정보를 추출하여 category_range에 넣어주었다.
이후 진도율에 대한 정보를 활용하기 위해 미리 리스트화 하여 progress_rate에 넣어주었다.

그리고 진도율을 강의 주차로 변환 할 필요가 있었는데, 각 주차별 진도율은 위와 같다. (강의마다 수강 시간과 분량이 다르기 때문)
#범주를 구분하는 기준 bins 처음(0)과 끝(100) 잊지 말고 기입 해주세요!
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
#구분한 범주의 라벨 labels
labes=[0,1,2,3,4,5]
#범주화에 사용하는 함수 pd.cut
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labes)
#결과물을 테이블로 변경하기
cuts = pd.DataFrame(cuts)
cuts.tail()
#concat() 함수를 이용하여, 테이블을 병합 할수 있습니다
cohort_data = pd.concat([cohort_data,cuts],axis=1, join='inner')
cohort_data.head()
#그래서, 귀찮더라도, 우리가 원하는 컬럼의 이름을 다 작성해 줍시다!
cohort_data.columns=['created_at','user_id','name','progress_rate','start_time','start_week',"week"]
cohort_data.head()
#기존의 테이블을, start_week와, week로 묶어줍니다!
grouping = cohort_data.groupby(['start_week','week'])
grouping.head()
cohort_data = grouping['user_id'].apply(pd.Series.nunique)
cohort_data = pd.DataFrame(cohort_data)
cohort_data.head(20)
#첫 주가 31주니 변수를 하나 만들어 줍니다!
f=31
#처음 수강 시작한 주의 범위가 {31,32,33,34,35,36} 이니, range(6)으로 합시다!
for i in range(6):
#5주차의 강의가 마지막이고, 0주차까지 이니, 시작은 5에서 시작해 1씩 0까지 감소 시킬수 있어요!
for j in range(5, 0, -1):
cohort_data.at[(f,j-1), 'user_id'] = int(cohort_data.at[(f,j),'user_id']) + int(cohort_data.at[(f,j-1),'user_id'])
#주차는(31부터 32 33..) 1씩 늘어나죠?
f=f+1
cohort_data = cohort_data.reset_index()
cohort_data.head(20)
cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_countsbins를 이용해 각 구간을 나누어주고 label을 달아주었다. 이후 pd.cut 함수를 이용하여 범주화를 해주고 테이블로 변환해주었다.
이후 concat()함수를 이용하여 테이블을 병합하고, 칼럼의 이름을 다시 작성해서 깔끔한 테이블을 만들어주었다.
이후 start_week와 week을 묶어주어 히트맵으로 시각화 하기위한 기반을 마련하고 pd.Series.nunique와 pd.DataFrame을 이용하여 수강 수를 구하고 테이블로 변환해주었는데 이 부분부터는 새로운 내용이라 이해하는데 약간 어려움이 있어서 주말에 복습을 진행하고 다시 한번 내용을 정리하겠다.
# 앞서 만든 피벗 테이블을 retention 변수에 저장하기
retention = cohort_counts
#각 주(week) 별 최초 수강생 수만 가져오기 (나눠줄때, 분모가 되는 부분!)
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
# 표의 단일 데이터에 최초 수강생의 수를 나누어, 각 주당 수강생 수강율 나타내기!
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention.head()
#각 수치 퍼센트로 변경하기
#round 함수로 3자리 수에서 반올림 한 후, 100을 곱해 줍니다!
retention.round(3)*100
#테이블 크기 설정 하기
plt.figure(figsize=(10,8))
sns.heatmap(data=retention,
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
#y축 레이블 축 변경 하기
plt.yticks(rotation=360)
#테이블 보여주기
plt.show()이후 데이터들을 가공 통해 데이터를 피벗 테이블로 만들었으니, matplotlib 라이브러리를 통해 히트맵으로 나타내 주었다.

오늘은 기존의 내용을 모두 복습하고, 데이터 가공에 대한 심화적인 내용을 배웠다. 피벗 테이블화 하기위해 데이터를 가공하고 테이블을 합치고 하면서 깔끔한 데이터로 변환하는 것이 매우 신기했는데, 복습을 통해서 반드시 내 것으로 만들것이다.
'내일배움캠프 > TIL(Today I Learned)' 카테고리의 다른 글
| [2026/03/17] 내일배움캠프 7일차 TIL (0) | 2026.03.17 |
|---|---|
| [2026/03/16] 내일배움캠프 6일차 TIL & KPT 회고 (0) | 2026.03.16 |
| [2026/03/12] 내일배움캠프 4일차 TIL (0) | 2026.03.12 |
| [2026/03/11] 내일배움캠프 3일차 TIL (0) | 2026.03.11 |
| [2026/03/10] 내일배움캠프 2일차 TIL (0) | 2026.03.10 |